 Infinite Row Model
Infinite Row Model
If you are an Enterprise user you should consider using
the Server-Side Row Model
instead of the Infinite Row Model . It offers the same functionality with many more features. The differences between
row models can be found in the Row Models page.
Infinite scrolling allows the grid to lazy-load rows from the server depending on what the scroll position is of the
grid. In its simplest form, the more the user scrolls down, the more rows get loaded.
The grid will have an ‘auto extending’ vertical scroll. That means as the scroll reaches the bottom position, the grid
will extend the height to allow scrolling even further down, almost making it impossible for the user to reach the
bottom. This will stop happening once the grid has extended the scroll to reach the last record in the table.
How it Works
The grid will ask your application, via a datasource, for the rows in blocks. Each block
contains a subset of rows of the entire dataset. The following diagram is a high-level overview.
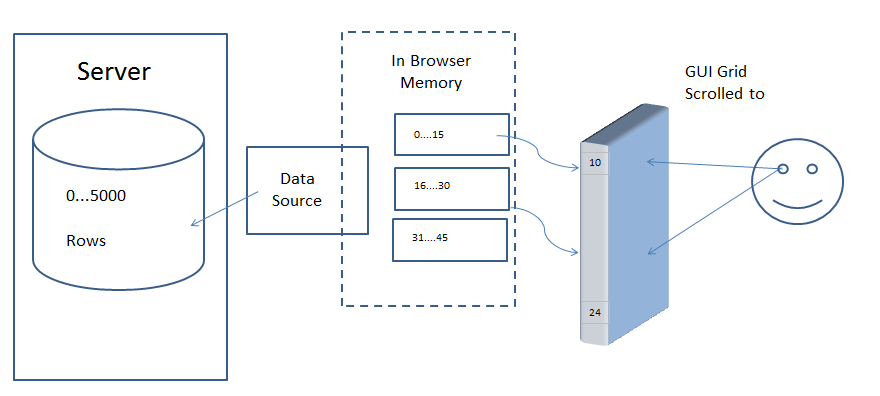
When the grid scrolls to a position where there is no corresponding block of rows loaded, the model
uses the provided datasource to get the rows for the requested block. In the diagram, the datasource
is getting the rows from a database in a remote server.
Turning On Infinite Scrolling
To turn on infinite scrolling, you must set the grid property rowModelType="infinite":
dag.AgGrid(
rowModelType="infinite",
# other props
)
Datasource Interface
In a nutshell, every time the grid wants more rows, it will call getRows() on the datasource. Use the getRowsRequest
property as the Input of the Dash callback. The callback responds with the rows requested. Use getRowsResponse as
the Output of the callback to provide data to the grid.
-
getRowsRequest(dict; optional): Infinite Scroll, Datasource interface.getRowsRequestis a dict with keys:startRow(number; optional): The first row index to get.endRow(number; optional): The first row index to NOT get.filterModel(dict; optional): If filtering, what the filter model is.sortModel(list of dicts; optional): If sorting, what the sort model is.successCallback(function; optional): Function to call when the request is successful.failCallback(function; optional): Function to call when the request fails.context(boolean | number | string | dict | list; optional): The grid context object.
-
getRowsResponse(dict; optional): Serverside model data response object.getRowsResponseis a dict with keys:rowCount(number; optional): Current row count, if known.rowData(list of dicts; optional): Data retrieved from the server.storeInfo(boolean | number | string | dict | list; optional): Any extra info for the grid to associate with
this load.
Block Cache
The grid keeps the blocks in a cache. You have the choice to never expire the blocks, or to set a limit to the number of
blocks kept. If you set a limit, then as you scroll down, previous blocks will be discarded and will be loaded again if
the user scrolls back up. The maximum blocks to keep in the cache is set using the Grid Option maxBlocksInCache:
dashGridOptions = {"maxBlocksInCache": 10}
Block Size
The block size is set using the Grid Option cacheBlockSize. This is how many rows each block in the cache should
contain. Each call to your datasource will be for one block.
dashGridOptions = {"cacheBlockSize": 100}
Debounce Block Loading
It is also possible to debounce the loading to prevent blocks loading until scrolling has stopped. This can be
configured using the Grid Option blockLoadDebounceMillis:
dashGridOptions = {"blockLoadDebounceMillis": 1000}
Aggregation and Grouping
Aggregation and grouping are not available in infinite scrolling. This is because to do so would require the grid
knowing the entire dataset, which is not possible when using the Infinite Row Model. If you need aggregation and / or
grouping for large datasets, check
the Server-Side Row Model for
doing aggregations on the server-side.
Sort and Filter
The grid cannot do sorting or filtering for you, as it does not have all the data. Sorting or filtering must be done on
the server-side. For this reason, if the sort or filter changes, the grid will use the datasource to get the data again
and provide the sort and filter state to you.
Simple Example: No Sorting or Filtering
The example below makes use of infinite scrolling and caching. Note that the grid will load more data when you bring the
scroll all the way to the bottom.
```python
import dash_ag_grid as dag
from dash import Dash, Input, Output, html, no_update, callback
import pandas as pd
app = Dash()
df = pd.read_csv(
"https://raw.githubusercontent.com/plotly/datasets/master/ag-grid/olympic-winners.csv"
)
columnDefs = [
# this row shows the row index, doesn't use any data from the row
{
"headerName": "ID",
"maxWidth": 100,
# it is important to have node.id here, so that when the id changes (which happens when the row is loaded)
# then the cell is refreshed.
"valueGetter": {"function": "params.node.id"},
},
{"field": "athlete", "minWidth": 150},
{"field": "country", "minWidth": 150},
{"field": "year"},
{"field": "sport", "minWidth": 150},
{"field": "total"},
]
defaultColDef = {
"flex": 1,
"minWidth": 150,
"sortable": False,
"resizable": True,
}
app.layout = html.Div(
[
dag.AgGrid(
id="infinite-row-no-sort",
columnDefs=columnDefs,
defaultColDef=defaultColDef,
rowModelType="infinite",
dashGridOptions={
"rowSelection": {'mode': 'multiRow'},
"rowBuffer": 0,
# how big each page in our page cache will be, default is 100
"cacheBlockSize": 100,
# How many blocks to keep in the store. Default is no limit, so every requested block is kept.
# how many extra blank rows to display to the user at the end of the dataset, which sets the vertical
# scroll and then allows the grid to request viewing more rows of data.
# Default is 1, meaning show 1 row.
"cacheOverflowSize": 2,
# how many server side requests to send at a time. if user is scrolling lots, then the requests are
# throttled down
"maxConcurrentDatasourceRequests": 1,
# how many rows to initially show in the grid. having 1 shows a blank row, so it looks like the grid
# is loading from the users perspective
"infiniteInitialRowCount": 1000,
# how many pages to store in cache. default is undefined, which allows an infinite sized cache, pages
# are never purged. this should be set for large data to stop your browser from getting full of data
"maxBlocksInCache": 10,
},
),
],
)
@callback(
Output("infinite-row-no-sort", "getRowsResponse"),
Input("infinite-row-no-sort", "getRowsRequest"),
)
def infinite_scroll(request):
if request is None:
return no_update
partial = df.iloc[request["startRow"]: request["endRow"]]
return {"rowData": partial.to_dict("records"), "rowCount": len(df.index)}
if __name__ == "__main__":
app.run(debug=True)
```
Selection
Selection works on the rows in infinite scrolling by using
the Row IDs of the Row Nodes. If you do not provide Keys for the Row
Nodes, the index of the Row Node will be used. Using the index of the row breaks down when (server-side) filtering or
sorting, as these change the index of the Rows. For this reason, if you do not provide your
own Row IDs, then selection is cleared if sort or filter is changed.
To provide your own Row IDs, use the getRowId prop which will
return the Key for the data.
dag.AgGrid(
# the ID can be any string, as long as it's unique within your dataset
getRowId="params.data.ID"
)
Once you have a Row ID, the selection will persist across sorts and filters.
Example: Sorting, Filtering and Selection
The following example extends the example above by adding server-side sorting, filtering and persistent selection.
Any column can be sorted by clicking the header. When this happens, the datasource is called again with the new sort
options.
The columns Age, Country and Year can be filtered. When this happens, the datasource is called again with the new
filtering options.
When a row is selected, the selection will remain inside the grid, even if the grid gets sorted or filtered. Notice that
when the grid loads a selected row (e.g. select first row, scroll down so the first block is removed from cache, then
scroll back up again) the row is not highlighted until the row is loaded from the server. This is because the grid is
waiting to see what the ID is of the row to be loaded.
```python
import dash_ag_grid as dag
from dash import Dash, Input, Output, html, callback
import pandas as pd
app = Dash()
df = pd.read_csv("https://raw.githubusercontent.com/plotly/datasets/master/ag-grid/olympic-winners.csv")
df["index"] = df.index.astype(str)
columnDefs = [
{"field": "athlete", "suppressHeaderMenuButton": True},
{
"field": "age",
"filter": "agNumberColumnFilter",
"filterParams": {
"filterOptions": ["equals", "lessThan", "greaterThan"],
"maxNumConditions": 1,
},
},
{
"field": "country",
"filter": True
},
{
"field": "year",
"filter": "agNumberColumnFilter",
},
{"field": "athlete"},
{"field": "date"},
{"field": "sport", "suppressHeaderMenuButton": True},
{"field": "total", "suppressHeaderMenuButton": True},
]
defaultColDef = {
"flex": 1,
"minWidth": 150,
"sortable": True,
"resizable": True,
"floatingFilter": True,
}
app.layout = html.Div(
[
dag.AgGrid(
id="infinite-row-sort-filter-select",
columnDefs=columnDefs,
defaultColDef=defaultColDef,
rowModelType="infinite",
dashGridOptions={
# The number of rows rendered outside the viewable area the grid renders.
"rowBuffer": 0,
# How many blocks to keep in the store. Default is no limit, so every requested block is kept.
"maxBlocksInCache": 2,
"cacheBlockSize": 100,
"cacheOverflowSize": 2,
"maxConcurrentDatasourceRequests": 2,
"infiniteInitialRowCount": 1,
"rowSelection": {'mode': 'multiRow'},
},
getRowId="params.data.index",
),
],
)
operators = {
"greaterThanOrEqual": "ge",
"lessThanOrEqual": "le",
"lessThan": "lt",
"greaterThan": "gt",
"notEqual": "ne",
"equals": "eq",
}
def filter_df(dff, filter_model, col):
if "filter" in filter_model:
if filter_model["filterType"] == "date":
crit1 = filter_model["dateFrom"]
crit1 = pd.Series(crit1).astype(dff[col].dtype)[0]
if "dateTo" in filter_model:
crit2 = filter_model["dateTo"]
crit2 = pd.Series(crit2).astype(dff[col].dtype)[0]
else:
crit1 = filter_model["filter"]
crit1 = pd.Series(crit1).astype(dff[col].dtype)[0]
if "filterTo" in filter_model:
crit2 = filter_model["filterTo"]
crit2 = pd.Series(crit2).astype(dff[col].dtype)[0]
if "type" in filter_model:
if filter_model["type"] == "contains":
dff = dff.loc[dff[col].str.contains(crit1)]
elif filter_model["type"] == "notContains":
dff = dff.loc[~dff[col].str.contains(crit1)]
elif filter_model["type"] == "startsWith":
dff = dff.loc[dff[col].str.startswith(crit1)]
elif filter_model["type"] == "notStartsWith":
dff = dff.loc[~dff[col].str.startswith(crit1)]
elif filter_model["type"] == "endsWith":
dff = dff.loc[dff[col].str.endswith(crit1)]
elif filter_model["type"] == "notEndsWith":
dff = dff.loc[~dff[col].str.endswith(crit1)]
elif filter_model["type"] == "inRange":
if filter_model["filterType"] == "date":
dff = dff.loc[
dff[col].astype("datetime64[ns]").between_time(crit1, crit2)
]
else:
dff = dff.loc[dff[col].between(crit1, crit2)]
elif filter_model["type"] == "blank":
dff = dff.loc[dff[col].isnull()]
elif filter_model["type"] == "notBlank":
dff = dff.loc[~dff[col].isnull()]
else:
dff = dff.loc[getattr(dff[col], operators[filter_model["type"]])(crit1)]
elif filter_model["filterType"] == "set":
dff = dff.loc[dff[col].astype("string").isin(filter_model["values"])]
return dff
@callback(
Output("infinite-row-sort-filter-select", "getRowsResponse"),
Input("infinite-row-sort-filter-select", "getRowsRequest"),
)
def infinite_scroll(request):
dff = df.copy()
if request:
if request["filterModel"]:
filters = request["filterModel"]
for f in filters:
try:
if "operator" in filters[f]:
if filters[f]["operator"] == "AND":
dff = filter_df(dff, filters[f]["condition1"], f)
dff = filter_df(dff, filters[f]["condition2"], f)
else:
dff1 = filter_df(dff, filters[f]["condition1"], f)
dff2 = filter_df(dff, filters[f]["condition2"], f)
dff = pd.concat([dff1, dff2])
else:
dff = filter_df(dff, filters[f], f)
except:
pass
if request["sortModel"]:
sorting = []
asc = []
for sort in request["sortModel"]:
sorting.append(sort["colId"])
if sort["sort"] == "asc":
asc.append(True)
else:
asc.append(False)
dff = dff.sort_values(by=sorting, ascending=asc)
lines = len(dff.index)
if lines == 0:
lines = 1
partial = dff.iloc[request["startRow"]: request["endRow"]]
return {"rowData": partial.to_dict("records"), "rowCount": lines}
if __name__ == "__main__":
app.run(debug=True)
```
When performing multiple row selections using shift-click, it is possible that not all rows are available in memory if
the configured value ofmaxBlocksInCachedoesn’t cover the range. In this case multiple selections will not be
allowed.
Specify Selectable Rows
It is also possible to specify which rows can be selected via the isRowSelectable function.
For instance in the example below, we only allow rows where the data.country property is the ‘United States’ like
this:
dashGridOptions = {
"isRowSelectable": {
"function": "params.data.country === 'United States'"
}
}
Note that we have also included an optional checkbox to help highlight which rows are selectable.
```python
import dash_ag_grid as dag
from dash import Dash, Input, Output, html, no_update, callback
import pandas as pd
app = Dash()
df = pd.read_csv(
"https://raw.githubusercontent.com/plotly/datasets/master/ag-grid/olympic-winners.csv"
)
columnDefs = [
# this row shows the row index, doesn't use any data from the row
{
"headerName": "ID",
"maxWidth": 100,
# it is important to have node.id here, so that when the id changes (which happens
# when the row is loaded) then the cell is refreshed.
"valueGetter": {"function": "params.node.id"},
},
{"field": "athlete", "minWidth": 150},
{"field": "country", "minWidth": 150},
{"field": "year"},
{"field": "sport", "minWidth": 150},
{"field": "total"},
]
defaultColDef = {
"flex": 1,
"minWidth": 150,
"sortable": False,
"resizable": True,
}
app.layout = html.Div(
[
dag.AgGrid(
id="infinite-row-model-is-selectable",
columnDefs=columnDefs,
defaultColDef=defaultColDef,
rowModelType="infinite",
dashGridOptions={
# The number of rows rendered outside the viewable area the grid renders.
"rowBuffer": 0,
# How many blocks to keep in the store. Default is no limit, so every requested block is kept.
"maxBlocksInCache": 10,
"cacheBlockSize": 100,
"cacheOverflowSize": 2,
"maxConcurrentDatasourceRequests": 1,
"infiniteInitialRowCount": 1000,
"rowSelection": {
'mode': 'multiRow',
"isRowSelectable": {"function": "params.data.country === 'United States'"}
},
},
),
html.Div(id="infinite-row-model-output-is-selectable"),
],
)
@callback(
Output("infinite-row-model-output-is-selectable", "children"),
Input("infinite-row-model-is-selectable", "selectedRows"),
)
def display_selected(selected_rows):
if selected_rows:
athlete_set = {row['athlete'] for row in selected_rows}
return f"You selected athlete{'s' if len(athlete_set) > 1 else ''} {', '.join(athlete_set)}"
return no_update
@callback(
Output("infinite-row-model-is-selectable", "getRowsResponse"),
Input("infinite-row-model-is-selectable", "getRowsRequest"),
)
def infinite_scroll(request):
if request is None:
return no_update
partial = df.iloc[request["startRow"]: request["endRow"]]
return {"rowData": partial.to_dict("records"), "rowCount": len(df.index)}
if __name__ == "__main__":
app.run(debug=True)
```
Loading Spinner
The examples on this page use a loading spinner to show if the row is waiting for its data to be loaded. The grid does
not provide this, rather it is a simple rendering technique used in the examples. If the data is loading, then
the rowNode will have no ID, so if you use the ID as the value, the cell will get refreshed when the ID is set.
To see the spinners, scroll down quickly. This example has a 2-second delay to simulate a longer running callback to
fetch data.
View Custom Loading Cell Renderer Component used for this example
View Custom Loading Cell Renderer Component used for this example
This JavaScript function must be added to the dashAgGridComponentFunctions.js file in the assets folder.
See Custom Components for more
information.
Note that in this example, the loading spinner is a component from the dash-bootstrap-components
library. In the app, it’s necessary to import the dash_components_components library and include a Bootstrap stylesheet, even if there
are no other Bootstrap components used in the app. For example:
app.py
import dash_bootstrap_components as dbc
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
assets/dashAgGridComponentFunctions.js
var dagcomponentfuncs = (window.dashAgGridComponentFunctions = window.dashAgGridComponentFunctions || {});
dagcomponentfuncs.SpinnerCellRenderer = function (props) {
if (props.value !== undefined) {
return props.value;
} else {
return React.createElement(window.dash_bootstrap_components.Spinner, {color: "primary", size: "sm"})
}
}
```python
import time
import dash_ag_grid as dag
from dash import Dash, Input, Output, html, no_update, callback
import pandas as pd
# required for the SpinnerCellRenderer
import dash_bootstrap_components as dbc
app = Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
df = pd.read_csv(
"https://raw.githubusercontent.com/plotly/datasets/master/ag-grid/olympic-winners.csv"
)
df["ID"] = df.index
columnDefs = [
{"field": "ID", "maxWidth": 100, "cellRenderer": "SpinnerCellRenderer"},
{"field": "athlete", "minWidth": 150},
{"field": "country", "minWidth": 150},
{"field": "year"},
{"field": "sport", "minWidth": 150},
{"field": "total"},
]
defaultColDef = {
"flex": 1,
"minWidth": 150,
"sortable": False,
"resizable": True,
}
app.layout = html.Div(
[
dag.AgGrid(
id="infinite-row-model-spinner",
columnDefs=columnDefs,
defaultColDef=defaultColDef,
rowModelType="infinite",
dashGridOptions={
# The number of rows rendered outside the viewable area the grid renders.
"rowBuffer": 0,
# How many blocks to keep in the store. Default is no limit, so every requested block is kept.
"maxBlocksInCache": 10,
"cacheBlockSize": 100,
"cacheOverflowSize": 2,
"maxConcurrentDatasourceRequests": 1,
"infiniteInitialRowCount": 1000,
},
),
],
)
@callback(
Output("infinite-row-model-spinner", "getRowsResponse"),
Input("infinite-row-model-spinner", "getRowsRequest"),
)
def infinite_scroll(request):
# simulate slow callback
time.sleep(2)
if request is None:
return no_update
partial = df.iloc[request["startRow"]: request["endRow"]]
return {"rowData": partial.to_dict("records"), "rowCount": len(df.index)}
if __name__ == "__main__":
app.run(debug=True)
```
Pagination
As with all row models, it is possible to enable pagination with infinite scrolling. With infinite scrolling, it is
possible to mix and match with the configuration to achieve different effects. The following examples are presented:
| Example | Page Size | Block Size | Comment |
|---|---|---|---|
| Example 1 | Auto | Large | Most Recommended |
| Example 2 | Equal | Equal | Recommended Sometimes |
Having smaller infinite blocks size than your pagination page size is not supported
You must have infinite block size greater than or equal to the pagination page size. If you have a smaller block size,
the grid will not fetch enough rows to display one page. This breaks how infinite scrolling works and is not
supported.
Example 1: Auto Pagination Page Size, Large Infinite Block Size
This example is the recommended approach. The infinite block size is larger than the pages size, so the grid loads data
for a few pages, allowing the user to hit ‘next’ a few times before a server sided call is needed.
View Custom Loading Cell Renderer Component used for this example
View Custom Loading Cell Renderer Component used for this example
This JavaScript function must be added to the dashAgGridComponentFunctions.js file in the assets folder.
See Custom Components for more
information.
var dagcomponentfuncs = (window.dashAgGridComponentFunctions = window.dashAgGridComponentFunctions || {});
dagcomponentfuncs.SpinnerCellRenderer = function (props) {
if (props.value !== undefined) {
return props.value;
} else {
return React.createElement(window.dash_bootstrap_components.Spinner, {color: "primary", size: "sm"})
}
}
```python
import dash_ag_grid as dag
from dash import Dash, Input, Output, html, no_update, callback
import pandas as pd
import time
app = Dash()
df = pd.read_csv(
"https://raw.githubusercontent.com/plotly/datasets/master/ag-grid/olympic-winners.csv"
)
columnDefs = [
# this row shows the row index, doesn't use any data from the row
{
"headerName": "ID",
"maxWidth": 100,
# it is important to have node.id here, so that when the id changes (which happens
# when the row is loaded) then the cell is refreshed.
"valueGetter": {"function": "params.node.id"},
"cellRenderer": "SpinnerCellRenderer",
},
{"field": "athlete", "minWidth": 150},
{"field": "country", "minWidth": 150},
{"field": "year"},
{"field": "sport", "minWidth": 150},
{"field": "total"},
]
defaultColDef = {
"flex": 1,
"minWidth": 150,
"sortable": False,
"resizable": True,
}
app.layout = html.Div(
[
dag.AgGrid(
id="infinite-row-model-pagination-auto",
columnDefs=columnDefs,
defaultColDef=defaultColDef,
rowModelType="infinite",
dashGridOptions={
# The number of rows rendered outside the viewable area the grid renders.
"rowBuffer": 0,
# How many blocks to keep in the store. Default is no limit, so every requested block is kept.
"maxBlocksInCache": 2,
"cacheBlockSize": 100,
"cacheOverflowSize": 2,
"maxConcurrentDatasourceRequests": 2,
"infiniteInitialRowCount": 1,
"rowSelection": {'mode': 'multiRow'},
"pagination": True,
"paginationAutoPageSize": True,
},
),
],
)
@callback(
Output("infinite-row-model-pagination-auto", "getRowsResponse"),
Input("infinite-row-model-pagination-auto", "getRowsRequest"),
)
def infinite_scroll(request):
# simulate slow callback
time.sleep(2)
if request is None:
return no_update
partial = df.iloc[request["startRow"]: request["endRow"]]
return {"rowData": partial.to_dict("records"), "rowCount": len(df.index)}
if __name__ == "__main__":
app.run(debug=True)
```
Example 2: Equal Pagination Page Size and Large Infinite Block Size
This example demonstrates having the page and block sizes equal. Here the server is hit every time a new page is
navigated to.
View Custom Loading Cell Renderer Component used for this example
View Custom Loading Cell Renderer Component used for this example
This JavaScript function must be added to the dashAgGridComponentFunctions.js file in the assets folder.
See Custom Components for more
information.
var dagcomponentfuncs = (window.dashAgGridComponentFunctions = window.dashAgGridComponentFunctions || {});
dagcomponentfuncs.SpinnerCellRenderer = function (props) {
if (props.value !== undefined) {
return props.value;
} else {
return React.createElement(window.dash_bootstrap_components.Spinner, {color: "primary", size: "sm"})
}
}
```python
import dash_ag_grid as dag
from dash import Dash, Input, Output, html, no_update, callback
import pandas as pd
import time
app = Dash()
df = pd.read_csv(
"https://raw.githubusercontent.com/plotly/datasets/master/ag-grid/olympic-winners.csv"
)
columnDefs = [
# this row shows the row index, doesn't use any data from the row
{
"headerName": "ID",
"maxWidth": 100,
# it is important to have node.id here, so that when the id changes (which happens
# when the row is loaded) then the cell is refreshed.
"valueGetter": {"function": "params.node.id"},
"cellRenderer": "SpinnerCellRenderer",
},
{"field": "athlete", "minWidth": 150},
{"field": "country", "minWidth": 150},
{"field": "year"},
{"field": "sport", "minWidth": 150},
{"field": "total"},
]
defaultColDef = {
"flex": 1,
"minWidth": 150,
"sortable": False,
"resizable": True,
}
app.layout = html.Div(
[
dag.AgGrid(
id="infinite-row-model-pagination",
columnDefs=columnDefs,
defaultColDef=defaultColDef,
rowModelType="infinite",
dashGridOptions={
# The number of rows rendered outside the viewable area the grid renders.
"rowBuffer": 0,
# How many blocks to keep in the store. Default is no limit, so every requested block is kept.
"maxBlocksInCache": 2,
"cacheBlockSize": 100,
"cacheOverflowSize": 2,
"maxConcurrentDatasourceRequests": 2,
"infiniteInitialRowCount": 1,
"rowSelection": {'mode': 'multiRow'},
"pagination": True,
},
),
],
)
@callback(
Output("infinite-row-model-pagination", "getRowsResponse"),
Input("infinite-row-model-pagination", "getRowsRequest"),
)
def infinite_scroll(request):
# simulate slow callback
time.sleep(2)
if request is None:
return no_update
partial = df.iloc[request["startRow"]: request["endRow"]]
return {"rowData": partial.to_dict("records"), "rowCount": len(df.index)}
if __name__ == "__main__":
app.run(debug=True)
```